Xv6 笔记(二):调度
操作系统的一项主要工作是在多个程序间共享计算机的资源,让它们可以同时(或看起来像同时)运行。程序是在进程中执行的,同时运行多个程序实际上就是同时运行多个进程。进程往往比 CPU 多,所以就需要一个机制来让多个进程间分时共享 CPU(time-sharing)
理想情况下,这种共享对用户进程应该是透明的。一种常见的方法是通过将每个进程多路复用(multiplexing)到硬件 CPU 上,从而为每个进程提供它们拥有自己的虚拟 CPU 的错觉。要做到这一点,需要 CPU 在切换进程前,先记下旧进程的运行状态(或者叫上下文),等到下次它被唤醒时,再把之前的运行状态恢复回来,继续执行切换前要执行的指令,就好像没有发生过切换一样。这里的上下文就是进程(或者说线程,xv6 未支持多线程)的寄存器。保存和恢复 SP 和 PC 寄存器就意味着 CPU 切换了栈和正在执行的代码
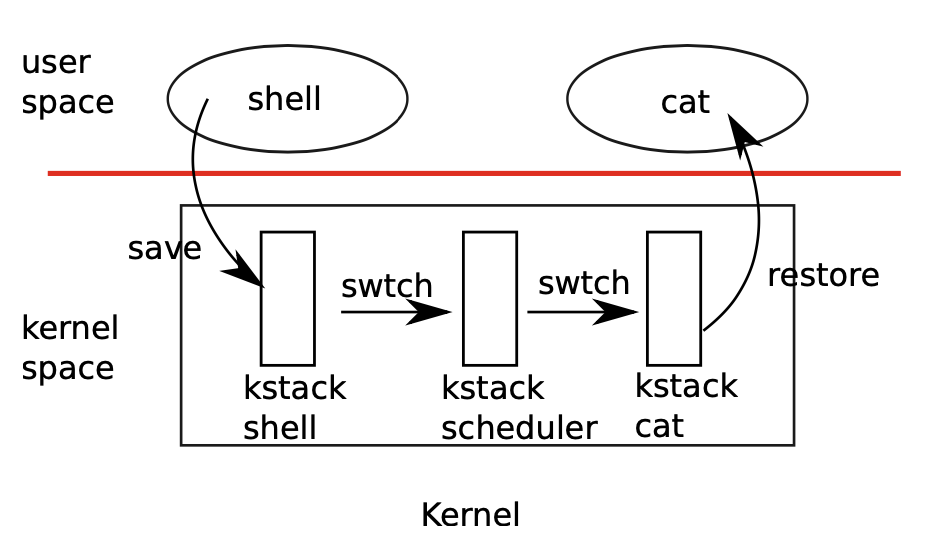
上图简单描述了用户进程切换的过程:1. 旧用户进程通过系统调用或中断切换到它的内核线程;2. 一次上下文切换(swtch)到 CPU 的调度器(scheduler)线程;3. 又一次上下文切换到新进程的内核线程;4. 从新线程的内核空间回到用户空间继续执行。每个 CPU 都有自己的调度器线程,它实际上就是一个寄存器值和栈的组合,在进程切换过程中恢复和保存。在单独的线程做这件事有助于抽象和简化调度逻辑,如果在旧进程的里做调度,其他 CPU 唤醒旧进程时会继续执行 swtch 之后的代码,这时进程的栈还是前一个 CPU 调度留下的,两个核使用同一个栈可能会带来很多问题
Xv6 在两种情况下会把 CPU 从一个进程切换到另一个:1. Xv6 会定时强制切换长时间运行的进程;2. 进程通过 sleep/wakeup 机制主动进入等待(设备/IO/子进程退出之类的)
前者是由定时器中断触发的,定时器中断源于与每个 RISC-V CPU 关联的时钟硬件,xv6 在启动时会在机器模式下修改 CLINT 硬件(core-local interruptor),生成一个在一定延迟后触发的中断,并配置中断处理程序和相关寄存器,开启中断开关。经过指定延时之后,硬件生成的中断会回调到定时器中断处理程序(timervec),后者再次修改 CLINT 硬件来配置下一次中断,然后向内核抛一个软件中断并返回。这里之所以不直接把时间中断交给内核处理是因为 RISC-V 要求定时器中断只能在机器模式配置和接收,运行在管理员模式的内核无法禁用它,但软件中断是可以禁用的,所以抛软件中断可以让内核自行配置是当前是否处理中断,以免关键操作被意外打断
抛出的软件中断后内核或用户进程通过 trap 机制暂停当前正在执行的代码,转而走到相应的处理程序,中断处理程序从特定寄存器读到是定时器中断,便调用 yield 暂停执行、释放 CPU,从而进入调度逻辑
在三种情况下一些事件会导致 CPU 搁置正在执行的指令序列,强制转向执行用于处理该事件的特殊代码:1. system call,用户程序通过 ecall 调用内核服务,引起 CPU 从用户模式转向管理员模式执行内核代码;2. exception,用户或内核执行了非法指令(除以 0、访问非法地址等),抛出异常;3. 设备中断,硬件设备执行完读写等操作时会触发来引起关注。这几种情况统称为 trap,处理中断的特殊代码为 trap handler
上下文切换机制可以让中断和进程切换对用户进程透明,但还是需要有一种机制来让进程能主动让出 CPU,进入等待被某些事件唤醒的状态,例如 console 程序可以在用户没有输入进入睡眠状态,让 CPU 先执行其他进程,在收到用户输入的事件后再被唤醒和处理输入的字符。Xv6 里实现这一机制的是 sleep 和 wakeup,也常叫条件同步(conditional synchronization)。进程 sleep 时监听的条件或事件称为 sleep channel(内核里的 sleep channel 通常是某些数据结构的内存地址),例如当用户用键盘输入的字符时,xv6 会收到一个 RISC-V 的设备中断,检查发现是来源是用户输入后就从特定的物理地址读取输入的字符,添加到 console 的输入字符 buffer 里并通过监听的 channel 唤醒 console
多个进程可以同时监听同一个 channel,条件触发时 wakeup 会把所有正在监听的进程设为可运行状态,然后由调度机制来把它们唤醒。如果唤醒的条件是某些资源(例如 pipe),只能被使用一次,那么这一资源只有第一个操作系统被唤醒的进程能消费到,后被唤醒的其他进程会发现条件不满足(资源没有了),唤醒只是一个“误会”,便再次进入睡眠和等待,这一现象叫做惊群问题(thundering herd problem),大量进程被误唤醒后再进入 sleep 会导致大量 CPU 资源被浪费在上下文切换上。解决问题的一种办法是把需要和不需要唤醒所有等待进程的 wakeup 调用明确区分成两个函数,在只需要唤醒一个进程的场景用 signal,需要唤醒多个进程的用 broadcast;另一种思路是用信号量,明确指出有多少资源或唤醒次数可用
使用 sleep/wakeup 机制的另一个例子是另一对与调度相关的系统调用 wait 和 exit。前者用于等待子进程退出,调用后会以当前进程数据结构的地址为 sleep channel 进入睡眠状态;后者供进程主动终止运行,进程结束运行后内核会尝试用父进程的地址作为 channel wakeup,这样如果有父进程在等待子进程退出,就会被唤醒并收到子进程的退出状态码
Xv6 在调度进程时采用的只是简单的轮询方案(遍历进程表找到一个可运行的进程然后运行它),现实中的操作系统往往会有更完善的调度方案来满足实际需求,例如引入进程优先级的概念,同时为了确保公平(低优先级进程也能得到执行)和高吞吐量,方案还会变得更加复杂,导致出现优先级反转(priority inversion,高优进程等待低优进程释放它持有的资源,但低优进程又得不到 CPU 资源来完成执行)、锁巡航(lock convoy,多个高优进程等待低优进程释放资源,CPU 资源会一直被浪费在高优进程的上下文切换中)等问题,解决这些问题又进一步增加了调度机制的复杂度